背景介绍
SRGAN(Supre Resolution Generative Adversarial Networks, 超分辨率生成式对抗网络):于2016年发表在CVPR上,图像处理的一个重要任务就是超分辨率,图像的大小是由分辨率决定的,常见的分辨率有128x128,256x256,512x512,1024x1024,像素越大,说明像素点越多,图像的表达能力更强,细节更加明显,看起来也会更加舒适。
分辨率提升的方法
在GAN问世以前,人们就做了许多关于分辨率提升的方法,其中最简单的也是最常用的方法就是插值法,在opencv库中有imresize函数,其中可以指定目标图像的尺寸,而且可以选择插值方法,一般选择双线性插值,但是插值方法有一个最致命的问题—模糊,插值的原理就是根据周围的点进行估计,因此插值的结果会导致某个区域的值都i非常接近,会导致照片模糊。
随着GAN的发展,人们发现GAN既然能够生成图像,能不能生成更高分辨率的图像,答案是肯定的,今天给小伙伴们介绍SRGAN的原理。
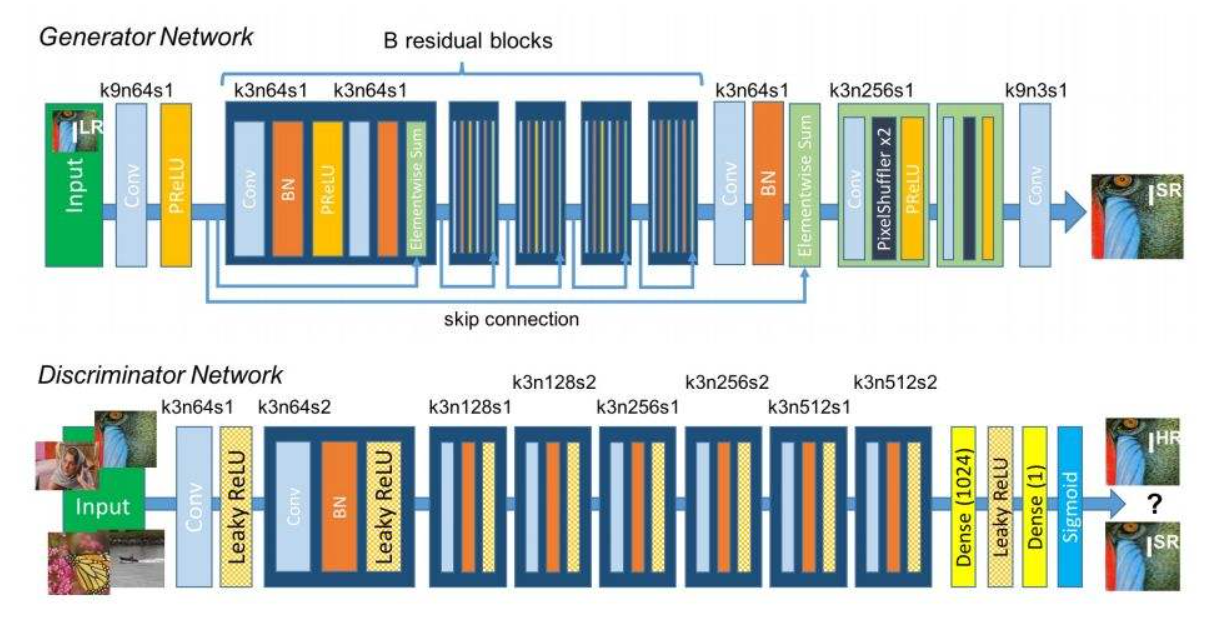
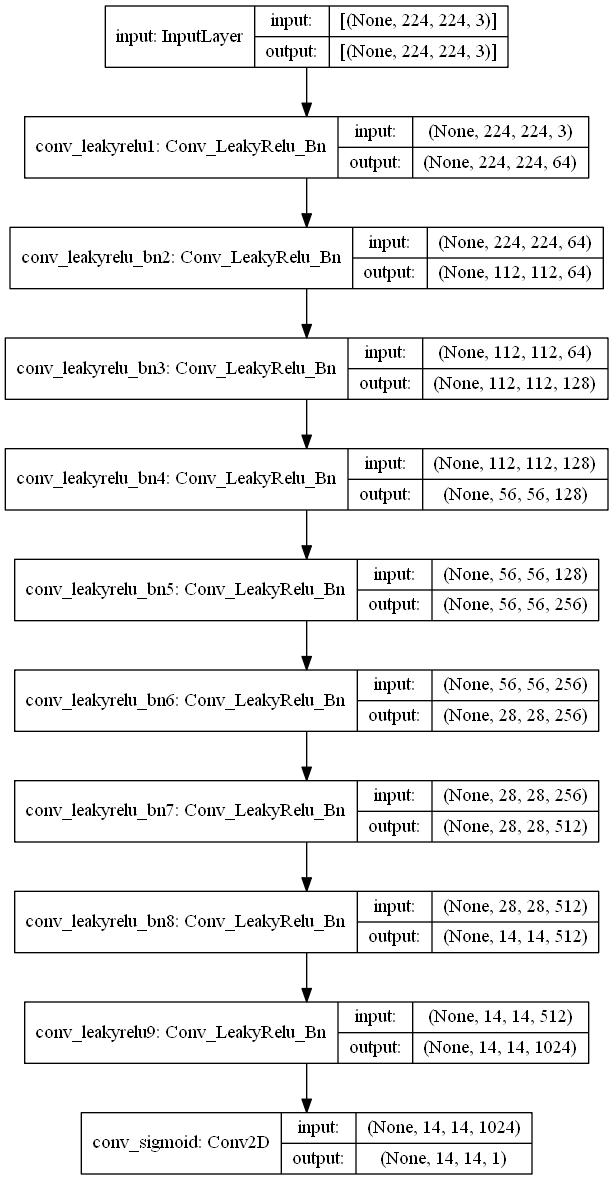
SRGAN引入了三个网络,一个是生成器,一个是判别器,还有一个是特征提取器(VGG19)
生成器的输入是低分辨率图像,输出是高分辨率图像,目的是根据输入的低分辨率图像生成高分辨率图像。
判别器的输入是高分辨率图像,输出是对输入图像的分类,目的是判断输入的图像是生成的高分辨率图像还是原始的高分辨率图像。
特征提取器的输入是高分辨率图像,输出是对高分辨率图像的特征提取,目的是使生成的图像和原始的高分辨率图像具有相同的特征。
SRGAN的特点
生成器使用ResNet结构+上采样对图像进行分辨率提升。
引入特征提取网络VGG19,对高分辨率特征进行提取。
特征提取损失函数采用均方误差,判别器损失函数采用二分类交叉熵。
对生成器损失函数的权重进行调节,使网络更多关注于生成的图像质量。
SRGAN图像分析

TensorFlow2.0实现
1 | import os |

模型运行结果

小技巧
- 图像输入可以先将其归一化到0-1之间或者-1-1之间,因为网络的参数一般都比较小,所以归一化后计算方便,收敛较快。
- 注意其中的一些维度变换和numpy,tensorflow常用操作,否则在阅读代码时可能会产生一些困难。
- 可以设置一些权重的保存方式,学习率的下降方式和早停方式。
- SRGAN对于网络结构,优化器参数,网络层的一些超参数都是非常敏感的,效果不好不容易发现原因,这可能需要较多的工程实践经验。
- 先创建判别器,然后进行compile,这样判别器就固定了,然后创建生成器时,不要训练判别器,需要将判别器的trainable改成False,此时不会影响之前固定的判别器,这个可以通过模型的_collection_collected_trainable_weights属性查看,如果该属性为空,则模型不训练,否则模型可以训练,compile之后,该属性固定,无论后面如何修改trainable,只要不重新compile,都不影响训练。
- 要注意使用VGG19特征提取网络权重时,因为VGG19的输入尺寸是224x224x3的,因此图像的尺寸要匹配,如果想生成更大尺寸的高分辨率图像,需要自己训练一个合适的特征提取网络权重。
- 在SRGAN的测试图像中,为了说明模型的优越性,左边为低分辨率图像直接resize到高分辨率图像的结果,右边为SRGAN生成的高分辨率图像的结果。只是训练了2000代,每一代只有2个图像就可以看出SRGAN的效果。小伙伴们可以选择更大的数据集,更加快速的GPU,训练更长的时间,这两种算法之间的差距会更加明显。
SRGAN小结
SRGAN是一种有效的超分辨率生成式对抗网络,从上图可以看出SRGAN模型的参数量只有7M,最近AI老图像复原引起了人们的注意,训练好SRGAN模型后可以运用在AI老图像复原,可以将原来拍摄的低分辨率的图像转化为清晰的高分辨率图像,是不是非常有趣呢?